
From Scalability to Sustainability: A 20-Year Retrospective on Deep Learning and Parameter-Efficient Fine-Tuning for Text Classification
Dari Skalabilitas ke Keberlanjutan: Tinjauan 20 Tahun tentang Pembelajaran Mendalam dan Penyesuaian Parameter yang Efisien untuk Klasifikasi Teks
DOI:
https://doi.org/10.21070/joincs.v9i1.1711Keywords:
Deep Learning, Natural Language Processing (NLP), Text Classification, Parameter-Efficient Fine-Tuning (PEFT), Technology Evolution, Scalability, Computational Efficiency, Sustainability, Green AIAbstract
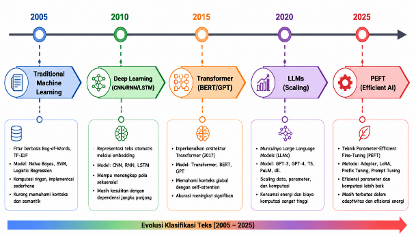
In the area of natural language processing (NLP), especially regarding text classification, earlier methods that relied on traditional machine learning are being increasingly replaced by neural network designs like convolutional neural networks and recurrent neural networks. Additionally, the rise of transformer-based models has led to considerable improvements in performance, though this comes with higher demands for computing power and energy usage. This paper provides a look back at the development of deep learning and Parameter-Efficient Fine-Tuning (PEFT) methods for text classification from 2005 to 2025. The research explores important technological advancements, evaluates the balance between performance, scalability, and efficient computing, and points out the rising concern for sustainability in the development of artificial intelligence. The findings show a transition from strategies aimed at simply increasing scale to those that focus on more efficiency. In this setting, PEFT has become an important advancement in easing the computing load without greatly impacting performance, although it still faces challenges in flexibility and energy consciousness. These insights are anticipated to lay the groundwork for more research into creating environmentally friendly NLP technologies.
References
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners (arXiv:2005.14165). arXiv. https://doi.org/10.48550/arXiv.2005.14165
[2] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arXiv:1810.04805). arXiv. https://doi.org/10.48550/arXiv.1810.04805
[3] Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
[4] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q. de, Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP (arXiv:1902.00751). arXiv. https://doi.org/10.48550/arXiv.1902.00751
[5] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv:2106.09685). arXiv. https://doi.org/10.48550/arXiv.2106.09685
[6] Joachims, T. (1998). Text categorization with Support Vector Machines: Learning with many relevant features. In C. Nédellec & C. Rouveirol (Eds.), Machine Learning: ECML-98 (Vol. 1398, pp. 137–142). Springer Berlin Heidelberg. https://doi.org/10.1007/BFb0026683
[7] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746–1751. https://doi.org/10.3115/v1/D14-1181
[8] Kitchenham, B., Pearl Brereton, O., Budgen, D., Turner, M., Bailey, J., & Linkman, S. (2009). Systematic literature reviews in software engineering – A systematic literature review. Information and Software Technology, 51(1), 7–15. https://doi.org/10.1016/j.infsof.2008.09.009
[9] Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning (arXiv:2104.08691). arXiv. https://doi.org/10.48550/arXiv.2104.08691
[10] Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation (arXiv:2101.00190). arXiv. https://doi.org/10.48550/arXiv.2101.00190
[11] McCallum, A., & Nigam, K. (2019). A Comparison of Event Models for Naive Bayes Text Classification.
[12] Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green AI. Communications of the ACM, 63(12), 54–63. https://doi.org/10.1145/3381831
[13] Snyder, H. (2019). Literature review as a research methodology: An overview and guidelines. Journal of Business Research, 104, 333–339. https://doi.org/10.1016/j.jbusres.2019.07.039
[14] Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and Policy Considerations for Deep Learning in NLP. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3645–3650. https://doi.org/10.18653/v1/P19-1355
[15] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need (arXiv:1706.03762). arXiv. https://doi.org/10.48550/arXiv.1706.03762
Published
How to Cite
License
Copyright (c) 2026 Andry Rachmadany, Ika Safitri Windiarti

This work is licensed under a Creative Commons Attribution 4.0 International License.




